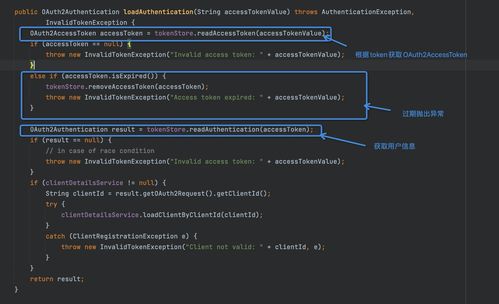
自动驾驶技术从实验室走向真实道路,正经历着从概念验证到规模化部署的关键转型。在这一过程中,工程化落地成为决定技术成败的核心环节,而其中数据处理与存储支持服务,则是支撑整个自动驾驶系统高效、安全运行的“数字基石”。
一、数据洪流:自动驾驶的“生命之源”
自动驾驶汽车堪称“数据怪兽”。每一辆测试或运营车辆,每日通过激光雷达、摄像头、毫米波雷达、GPS/IMU等传感器,可产生数TB甚至更多的原始数据。这些数据不仅包括道路场景、交通参与者、天气环境等感知信息,还涵盖车辆控制、决策规划、高精度地图定位等全链路信息。海量、多源、异构的数据流,构成了自动驾驶系统迭代优化的“燃料”,也对数据处理与存储提出了前所未有的挑战。
二、数据处理:从原始信息到驾驶智能的关键转化
数据处理是自动驾驶工程化的核心环节,其目标是将原始传感器数据转化为可供模型训练、仿真测试和在线推理的标准化信息。这一过程通常包括:
- 数据采集与同步:确保多传感器数据在时间戳、空间坐标系上的严格对齐,为后续融合提供基础。
- 数据清洗与标注:去除无效、重复或噪声数据,并对关键场景(如障碍物、车道线、交通标志)进行精细化标注,形成高质量数据集。
- 特征提取与融合:通过算法提取有效特征,并实现多传感器数据的融合,提升感知的鲁棒性与准确性。
- 仿真与闭环验证:利用处理后的数据构建仿真场景,进行算法测试与迭代,形成“数据驱动开发”的闭环。
高效的流水线工具、自动化标注平台、分布式计算框架(如Spark、Flink)以及强大的AI算力,已成为处理这一数据洪流的必备基础设施。
三、数据存储:为海量信息安家
面对持续增长的数据量,存储系统需要满足以下几方面需求:
- 高吞吐与低延迟:支持传感器数据的高速写入与模型的实时读取,尤其在在线学习与增量更新场景中至关重要。
- 可扩展性与成本控制:采用分布式存储架构(如Ceph、HDFS),实现容量的弹性扩展,同时通过冷热数据分层、压缩去重等技术降低存储成本。
- 数据安全与合规:自动驾驶数据涉及地理信息、个人隐私等敏感内容,必须建立完善的加密、访问控制、审计跟踪机制,并符合各地数据法规(如GDPR)。
- 版本管理与可追溯性:存储系统需支持数据集的版本管理,确保每一次算法迭代都可追溯到对应的数据快照,保障研发过程的可复现性。
云存储与边缘存储相结合的混合架构,正成为行业主流选择。热数据在边缘节点就近处理,冷数据及备份归档至云端,兼顾了性能与成本。
四、工程化落地的支撑服务
数据处理与存储并非孤立存在,而是需要一系列支撑服务来确保其高效运行:
- 数据湖/数据中台:构建统一的数据接入、治理、分析与服务平台,打破数据孤岛,提升数据利用效率。
- MLOps平台:将机器学习工作流(数据准备、模型训练、部署监控)标准化、自动化,加速模型迭代。
- 高可靠网络:保障车端、边缘与云端之间数据同步的稳定性与实时性,尤其在远程升级(OTA)与协同感知等场景中。
- 运维与监控体系:对数据流水线、存储集群的健康状态进行实时监控,实现故障预警与快速恢复。
五、未来展望
随着自动驾驶向L4/L5级迈进,数据处理与存储将面临更大挑战:仿真场景生成需要更逼真的合成数据;车路协同将引入更多路侧单元数据;“终生学习”要求车辆在运行中持续优化模型。隐私计算、联邦学习、神经辐射场(NeRF)等新技术,有望在保障数据安全的前提下,进一步释放数据价值。
在自动驾驶这场漫长的马拉松中,数据处理与存储支持服务虽处幕后,却如同“修路者”与“供粮官”,直接决定了技术落地的速度与质量。唯有筑牢这座数字基座,自动驾驶的规模化商用才能真正驶入快车道。