物联网时序数据库Apache IoTDB是一款专为工业物联网场景设计的高性能数据库,其存储引擎的高效性是其核心优势之一。本文将深入解析IoTDB存储引擎在数据处理与存储支持服务方面的核心原理。
一、 数据模型与分层存储结构
IoTDB采用“设备-时间序列”的数据模型,天然契合物联网设备按时间产生数据的特性。其存储引擎在逻辑上采用了分层、分区的设计:
- 存储组:是数据分区的基本单位,一个存储组对应一个独立的存储目录和写入锁,实现了数据的物理隔离与并行写入。用户可根据业务需求(如按设备、按项目)灵活划分存储组,优化I/O。
- 时间分区:在每个存储组内部,数据进一步按照时间范围(可配置)进行分区。这种设计极大地提升了按时间范围查询的效率,并便于实施老旧数据的冷热分层与生命周期管理。
二、 高效的数据处理流程
写入与查询是数据处理的两大核心,IoTDB存储引擎对此进行了深度优化。
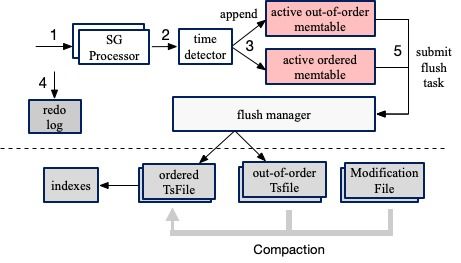
- 写入流程:数据首先进入写前日志(WAL),确保持久性。数据被写入内存中的写缓冲区(MemTable)。当MemTable写满或到达特定时间,会触发刷写操作,将其中的数据顺序、压缩地持久化到磁盘,形成一个不可变的顺序数据文件(TsFile)。这种LSM-Tree(日志结构合并树)的变体设计,将随机写转换为顺序写,显著提升了海量时间序列数据的高吞吐写入性能。
- 查询流程:查询请求会根据时间范围和存储组/分区信息,快速定位到相关的TsFile。TsFile内部数据按时间顺序存储,并包含丰富的索引(如时间索引、设备级索引)。引擎能够高效地进行时间过滤和值过滤,并利用预聚合的统计信息(如最大值、最小值)在文件级别进行快速剪枝,避免扫描无关数据,从而降低I/O开销,实现低延迟查询。
三、 核心存储支持服务
为保障数据可靠性、可用性与可管理性,存储引擎提供了一系列关键服务。
- 压缩与编码:这是存储引擎节省空间的核心手段。IoTDB支持多种针对时间序列数据的专用编码方式(如游程编码RLE、二阶差分编码TS_2DIFF、Gorilla编码等),在数据类型和模式已知的前提下,实现极高的压缩比。文件级别也支持压缩算法(如GZIP、LZ4),进一步降低存储成本。
- 索引机制:除了TsFile内部索引,IoTDB还支持可选的倒排索引。它建立测量值(传感器名)到包含该序列的TsFile的映射,使得在不指定设备路径、仅根据传感器名进行查询时,也能快速定位数据文件,增强了查询的灵活性。
- 数据生命周期管理与分层存储:引擎支持基于时间的数据过期策略(TTL),自动清理过期数据。结合时间分区,可以轻松实现冷热数据分离,将热数据存储在高速介质(如SSD),冷数据自动归档至低成本存储(如对象存储或HDFS),实现成本与性能的平衡。
- 数据一致性与恢复:写前日志(WAL)是保证数据持久性和崩溃恢复的关键。在系统异常重启后,可以通过重放WAL来恢复MemTable中未持久化的数据,确保数据不丢失。TsFile一旦生成即为不可变文件,这简化了并发控制与数据一致性管理。
四、 TsFile:存储的基石
TsFile是IoTDB自设计的列式存储文件格式,是上述所有特性的载体。
- 列式存储:同一时间序列的数据连续存储,便于高效压缩和针对单指标的快速扫描。
- 块与页结构:数据在文件中被组织为多个数据块(Chunk),每个块又包含多个页(Page)。页是压缩和I/O的基本单位,这种结构有利于平衡压缩效率与随机读取粒度。
- 丰富的元数据:文件头尾包含详细的元数据索引,如时间序列信息、统计信息、索引位置等,使得系统无需读取整个文件即可快速定位所需数据块。
Apache IoTDB的存储引擎通过其贴合物联网数据特性的分层模型、基于LSM-Tree的高效写优化、列式存储与专用编码带来的高压缩比、以及精细的索引与分区策略,共同构建了一个能够应对海量时序数据高吞吐写入、低成本存储与低延迟查询挑战的坚实基石。其内置的数据管理服务进一步确保了生产系统的可靠性、可维护性与经济性。