随着数据规模的不断增长和业务需求的实时化,大数据实时计算已成为现代数据处理架构中的核心组成部分。基于阿里云的表格存储(Table Store)和Blink流计算引擎,企业可以实现高效、稳定的大数据实时计算解决方案。本文将探讨基于表格存储和Blink的大数据实时计算最佳实践,涵盖数据处理、存储、计算流程以及优化策略,旨在为读者提供实用的技术指导。
数据处理与存储支持服务
表格存储作为阿里云提供的高性能、高可扩展的NoSQL数据存储服务,为实时计算提供了可靠的基础。它支持海量结构化数据的存储和访问,具备低延迟和高吞吐的特性,适用于实时数据写入和查询场景。结合Blink(阿里云基于Apache Flink优化的流计算引擎),可以实现从数据采集、处理到存储的全链路实时化。
在数据处理方面,Blink提供了强大的流式计算能力,包括事件时间处理、状态管理和窗口操作。通过将表格存储作为数据源或数据汇,Blink可以直接读取或写入数据,实现实时ETL、聚合分析和异常检测。例如,在电商场景中,用户行为数据可以实时写入表格存储,Blink则进行实时处理,输出推荐结果或监控指标。
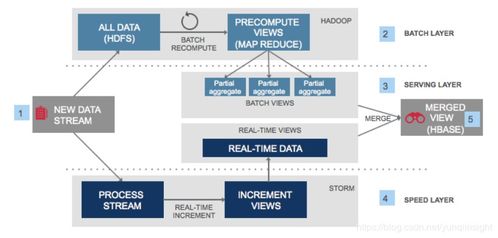
大数据实时计算架构
一个典型的基于表格存储和Blink的实时计算架构包括以下组件:
- 数据源:如日志、传感器数据或业务数据库变更,通过数据采集工具(如Logstash或DataX)实时推送到表格存储。
- 表格存储:作为中间数据层,存储原始数据或处理后的结果,支持高并发读写。
- Blink流计算引擎:从表格存储消费数据,执行实时计算逻辑,如过滤、聚合或机器学习推理,并将结果写回表格存储或其他下游系统(如数据仓库或消息队列)。
- 数据消费:应用系统从表格存储获取实时结果,用于仪表盘、报警或业务决策。
这种架构的优势在于其灵活性和扩展性。表格存储的自动分片和负载均衡机制确保了数据存储的稳定性,而Blink的分布式计算能力则支持水平扩展,以应对高流量场景。
最佳实践与优化策略
实施基于表格存储和Blink的实时计算方案时,需遵循以下最佳实践:
- 数据模型设计:在表格存储中,合理设计主键和数据分区,以优化查询性能。例如,使用时间戳作为分区键,便于时间范围查询。
- 计算逻辑优化:在Blink作业中,利用事件时间处理和状态后端(如RocksDB)来保证计算的准确性和容错性。避免频繁的状态操作,以减少延迟。
- 资源管理:根据数据量调整Blink集群的资源分配,确保计算任务不会因资源不足而延迟。阿里云提供了监控工具,可用于实时跟踪作业性能。
- 容错与一致性:通过Blink的检查点机制和表格存储的事务支持,实现端到端的一致性。在故障恢复时,系统能够从最近检查点重启,减少数据丢失。
- 成本控制:合理使用表格存储的容量型和性能型实例,结合Blink的自动扩缩容功能,平衡性能与成本。
应用场景与案例
基于表格存储和Blink的实时计算在多个领域有广泛应用。例如,在金融风控中,实时处理交易数据以检测欺诈行为;在物联网中,分析传感器数据以预测设备故障;在在线广告中,实时计算用户点击率以优化投放策略。这些场景都得益于系统的高吞吐和低延迟特性。
总结
基于表格存储和Blink的大数据实时计算方案提供了一种高效、可靠的数据处理路径。通过合理的架构设计和优化策略,企业能够快速响应业务变化,实现实时洞察。随着技术的演进,这一方案有望在更多场景中发挥关键作用。读者可参考阿里云云栖社区或CSDN博客获取更多实践案例和深度解析。