在云原生时代,以容器和Kubernetes为核心的应用部署方式已成为主流。从Linux Foundation的Cloud Native Computing Foundation(CNCF)视角,尤其是大型开源峰会如LC3所聚焦的趋势来看,Kubernetes环境下的可观测性,特别是日志管理,是保障应用稳定运行、快速排障与深度洞察的关键支柱。本文将探讨在Kubernetes架构下,如何系统性地实践日志的采集、存储与处理,并阐述相关的数据处理和存储支持服务。
一、Kubernetes日志采集:从容器到集群
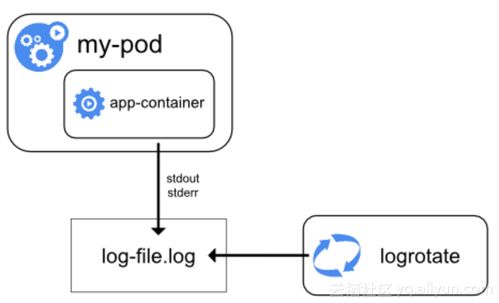
Kubernetes的日志采集面临独特挑战:容器生命周期短暂、日志输出分散(标准输出/文件)、多副本实例等。主流实践通常采用边车模式或DaemonSet模式的日志代理。
- 采集模式与技术选型
- DaemonSet模式:在每个Kubernetes节点上部署一个日志采集代理(如Fluentd、Fluent Bit、Filebeat)。代理负责采集该节点上所有容器的标准输出日志(通常位于
/var/log/containers/)以及可能的应用日志文件。这种方式资源占用相对集中,管理简单,是CNCF生态中最常见的方式。Fluentd/Fluent Bit作为CNCF毕业项目,与Kubernetes集成度极高。
- 边车模式:为每个需要特殊日志处理的应用Pod部署一个专用的日志采集边车容器。这种方式更灵活,可以为特定应用定制采集逻辑,但会显著增加资源开销和部署复杂度。通常与DaemonSet模式结合使用。
- 应用直接写入:鼓励应用程序通过SDK或API直接将结构化日志发送到中央日志服务(如Loki的Push API,或远程Syslog)。这减少了代理依赖,但对应用有侵入性。
- 最佳实践
- 结构化日志:在应用层面输出JSON等结构化日志,极大地方便后续的解析、过滤和索引。
- 使用元数据丰富日志:日志代理应自动为每条日志记录附加丰富的元数据,如Pod名称、命名空间、容器名称、节点名称、标签等。这是Kubernetes环境下进行多维度日志查询和关联的基础。
二、日志存储:平衡性能、成本与查询能力
海量日志的存储需要平衡查询性能、存储成本和长期保留需求。
- 存储架构
- 热存储/索引存储:用于近期高频查询的日志。要求低延迟、高吞吐的查询能力。常见选择:
- Elasticsearch:功能全面,强大的全文搜索和聚合分析能力,生态成熟,但运维复杂,资源消耗大。
- Grafana Loki:CNCF孵化项目,设计理念是“为日志而生的Prometheus”。它只索引元数据(标签),不对日志内容全文索引,将原始日志压缩存储于对象存储(如S3、MinIO)。这种设计使得其资源效率极高,成本远低于Elasticsearch,特别适合基于标签的Kubernetes日志查询模式。
- 冷存储/归档存储:用于满足合规性或历史分析需求的长期存储。通常使用高性价比的对象存储服务,如Amazon S3、Google Cloud Storage、Azure Blob Storage或开源的MinIO。Loki原生支持将数据存储在对象存储中,是其核心优势之一。
- 数据处理和存储支持服务
- 对象存储服务:作为日志存储的成本效益基石,提供几乎无限的扩展性、高持久性和按需付费模式。不仅是归档层,也正逐渐成为Loki等系统的主存储层。
- 托管搜索与分析服务:云厂商提供的Elasticsearch Service(如Amazon OpenSearch Service、Elastic Cloud)或托管Loki服务,可以大幅降低运维负担。
- 流处理与缓冲服务:在日志采集端与存储端之间,引入缓冲层以应对流量峰值和防止数据丢失。例如使用Apache Kafka或CNCF项目NATS作为日志流的中转与缓冲管道,实现解耦和背压管理。
三、日志处理与分析:从检索到洞察
存储之后的处理与分析是释放日志价值的关键。
- 处理流程
- 解析与转换:在采集端或通过独立的流处理管道(如使用Fluentd过滤器、Logstash或Vector),对非结构化日志进行解析(如Grok),提取关键字段,转换为统一的数据模型。
- 过滤与路由:根据日志级别、关键字或标签,将日志路由到不同的存储目的地或处理管道。
- 聚合与指标生成:实时分析日志流,生成业务或应用性能指标(如错误率、特定事务数量),并输入到监控系统(如Prometheus)进行告警。
- 查询与可视化
- 统一查询界面:Grafana已成为云原生领域事实上的可视化标准。它既可以连接Elasticsearch进行强大的全文检索,也可以连接Loki进行高效的标签查询,实现对日志、指标、链路的统一观测。
- 告警:基于日志模式(如大量错误日志出现)或计算出的指标,配置告警规则,实现主动问题发现。
四、实践与趋势展望
在LC3所代表的云原生社区视野下,Kubernetes日志管理的技术实践正朝着更云原生、更高效、更集成的方向发展:
- 融合与简化:Loki因其与Prometheus/Grafana栈的无缝集成和极低的资源开销,正获得越来越多的采纳,挑战着传统的ELK/EFK栈。
- 无代理与OpenTelemetry:随着OpenTelemetry项目的成熟,未来可能出现更统一的、无代理的遥测数据采集标准,将日志、指标、链路追踪的采集融合。
- 智能分析:结合机器学习,对日志进行异常检测、根因分析、趋势预测,从被动响应转向主动洞察。
- Serverless数据处理:利用云上的Serverless函数(如AWS Lambda)或流处理服务(如Google Cloud Dataflow),对日志进行按需的、事件驱动的处理,进一步降低运维复杂性。
构建Kubernetes下的日志体系,需要根据团队规模、技术栈、成本预算和对可观测性的需求,合理选择从采集、缓冲、存储到分析的工具链与服务。以CNCF生态为核心,采用如Fluent Bit + Loki + Grafana这样的轻量级组合,或结合云厂商的托管服务,能够高效地构建起一个强大、经济且面向未来的云原生日志平台。